데이터 집계
분포 및 요약 통계
- 데이터명.describe() : 컬럼별 값의 갯수, 평균, 표준편차, 최솟값, 최댓값, 사분위수 출력
df.describe()
대푯값
- min() : 최솟값
- max() : 최댓값
- mean() : 평균
- median() : 중앙값
- std() : 표준편차
- var() : 분산
- quantile(분위) : 분위수
df.min(numeric_only=True) # 숫자형만
df.quantile(0.25, numeric_only=True) # 1분위수
변수의 상관관계 확인
- 데이터명.corr()
df.corr(numeric_only=True)
# 시각화 참고
import seaborn as sns
import matplotlib.pyplot as plt
sns.heatmap(df.corr(numeric_only=True), annot=True)
plt.show()
Groupby
- 같은 값을 한 그룹으로 묶어서 여러가지 연산 및 통계를 구할 수 있음.
- 데이터명.groupby(컬럼명).연산및통계함수
1) 단일 그룹
- count() : 행의 갯수
- nunique() : 행의 유니크한 갯수
- sum() : 합
- mean() : 평균
- min() : 최솟값
- max() : 최댓값
- std() : 표준편차
- var() : 분산
df.groupby('Pclass').count()
df.groupby('Pclass').nunique()
df.groupby('Pclass').mean(numeric_only=True)
# 특정 열만
df.groupby('Pclass')[['Survived', 'Age']].mean()
2) 다중 그룹
df.groupby(['Sex', 'Pclass']).mean(numeric_only=True)
# 여러 개의 통계값
import numpy as np
df.groupby(['Sex', 'Pclass'])[['Survived', 'Age', 'SibSp']].aggregate([np.mean, np.min, np.max])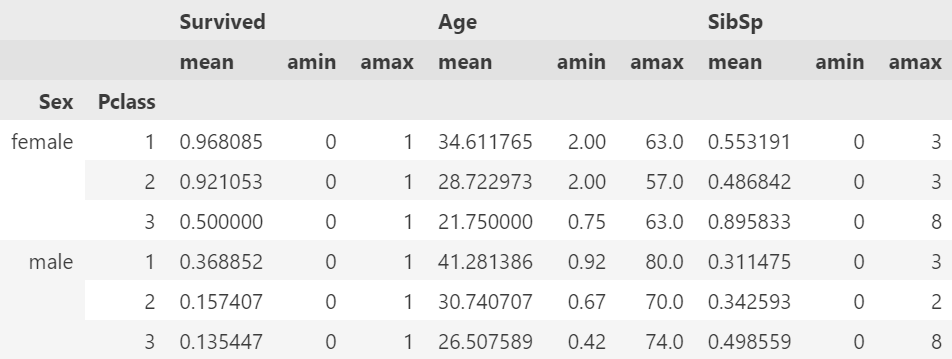
데이터 재구조화
crosstab
- 범주형 데이터를 비교분석할 때 유용
- pd.crosstab(index=행, columns=열, margins=True/False, normalize=True/False)
1) 범주별 갯수 구하기
- pd.crosstab(행, 열)
pd.crosstab(df['Sex'], df['Survived'])
2) 범주별 비율 구하기
- normalize = 'all' : 전체 합이 100%
- normalize = 'index' : 행별 합이 100%
- normalize = 'columns' : 열별 합이 100%
pd.crosstab(df['Sex'], df['Survived'], normalize='all')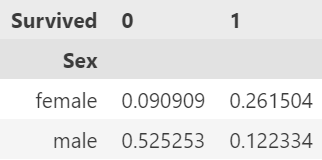
pd.crosstab(df['Sex'], df['Survived'], normalize='index')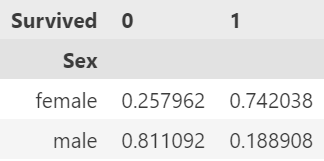
# 합계 컬럼 생성
pd.crosstab(df['Sex'], df['Survived'], normalize='columns', margins=True)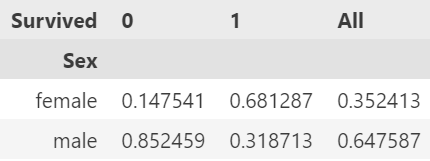
3) 다중 인덱스, 다중 컬럼의 범주표 구하기
pd.crosstab(index=[df['Sex'], df['Pclass']], columns=df['Survived'], normalize='columns')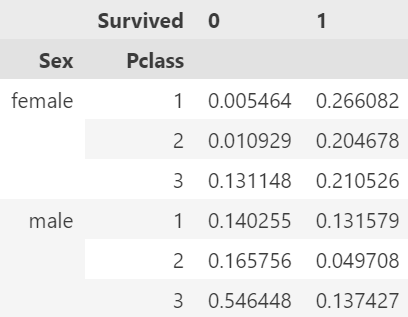
피벗 테이블
- 인덱스별, 컬럼별 값의 연산을 할 수 있음.
- pd.pivot_table(데이터명, index=, columns=, values=, aggfunc=)
1) 단일 인덱스, 단일 컬럼, 단일 값
pd.pivot_table(df, index='Sex', columns='Pclass', values='Survived', aggfunc='mean')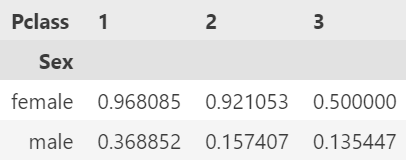
pd.pivot_table(df, index='Sex', columns='Survived', values='Age', aggfunc='mean', margins=True)
# margins=True : 행과 열 전체의 값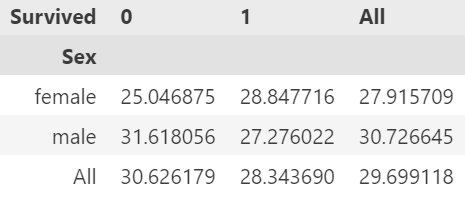
pd.pivot_table(df, index='Sex', columns='Survived', values='Age', aggfunc=['max', 'min', 'mean'])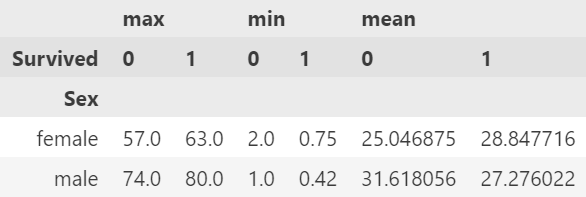
2) 다중 인덱스, 다중 컬럼, 다중 값
pd.pivot_table(df, index=['Sex', 'Pclass'], columns=['Survived','Embarked'], values=['Age', 'Fare'], aggfunc= 'mean')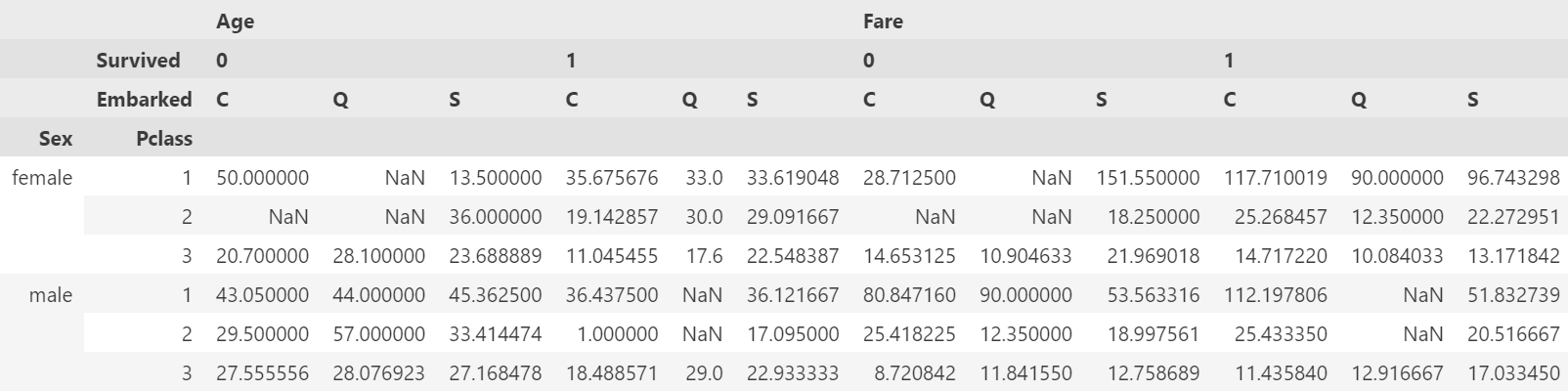
stack, unstack, melt
1) stack, unstack
- stack : 컬럼 레벨에서 인덱스 레벨로 데이터프레임 변경
- unstack : 인덱스 레벨에서 컬럼 레벨로 데이터프레임 변경
* 기본 pivot table
pivot = pd.pivot_table(df, index=['Sex', 'Pclass'], values=['Survived', 'Fare'], aggfunc=['mean', 'median', 'sum'])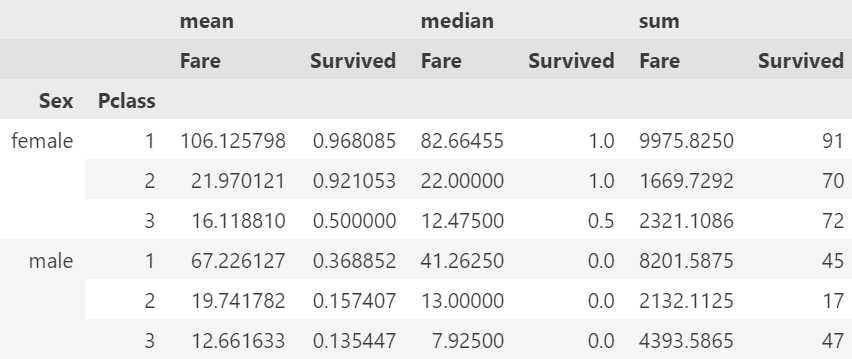
pivot.stack(0) # 컬럼의 첫번째 레벨을 인덱스로 내림.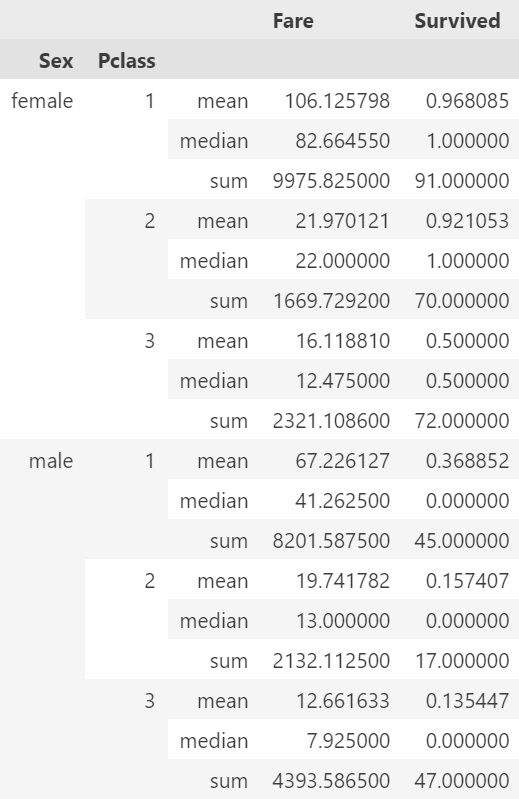
pivot.unstack(1) # 인덱스의 두번째 레벨을 컬럼으로 쌓음.
2) melt
- pd.melt(데이터명, id_vars=기준컬럼)
- 언피벗??
* 기본 데이터프레임
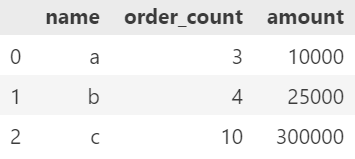
pd.melt(data, id_vars=['name'])
pd.melt(data, id_vars=['name'], var_name='type', value_name='val') # 컬럼 이름 바꿈.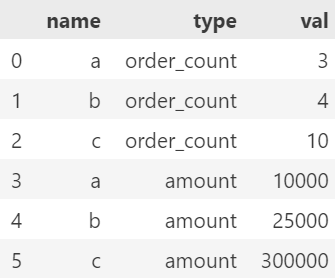
'Python > 데이터 분석' 카테고리의 다른 글
| [Python] 데이터 전처리 (2) | 2024.09.01 |
|---|
